主要是搜到的中文版解释都不是很能看得懂,所以搬运翻译一份Paul Krzyzanowski大佬写得简介。
(有我自己理解增加的部分,在意的朋友可以看原文)
Assigning Lamport & Vector Timestamps
Lamport Clocks
每个进程都维护一个Lamport时间戳计数器。
进程中的每个事件都用此计数器来标记。
在分配给事件时间戳时,时间戳计数器每次+1。
如果一个进程有四个事件a,b,c,d,则这些事件的Lamport时间戳分别为1、2、3、4。
例子🌰
下图显示了三个进程中的一系列事件。
些事件中的一些代表消息的发送,其他事件代表消息的接收,而其他事件只是本地事件(例如,将一些数据写入文件)。
根据简单的递增规则,我们得到了如下的时钟值。
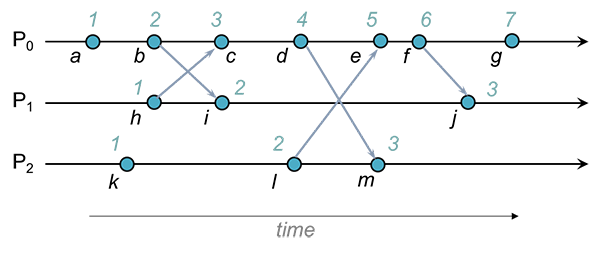
这个简单的递增计数器无法提供正确的事件因果关系。如果事件a在事件b之前发生,那么我们期望 clock(a) < clock(b)。
(而上图中进程之间的时间顺序显然是错乱的,比如b事件和i事件)
因此,Lamport时间戳生成需要额外的步骤。
要点
如果事件是发送消息,则该事件的时间戳与消息一起发送。
如果事件是接收消息,则进程的时间戳记计数器的当前值(在此事件之前刚刚增加)与接收到的消息中的时间戳记进行比较。
- 如果接收到的消息的时间戳大于或等于当前事件的时间戳,则事件和进程的时间戳计数器都将用接收到的消息中的时间戳值加1进行更新。这确保了接收到的事件的时间戳以及该进程上的所有其他时间戳将大于发送消息以及该进程上的所有先前消息的事件的时间戳。
情况一:接收到的消息的时间戳大于或等于当前事件的时间戳
在下图中,事件$P_1$中的事件i,是事件b在$P_0$中发送的消息的接收事件。
如果事件i只是正常的本地事件,则$P_1$将为其分配时间戳2。但是,由于接收到的时间戳为2(大于或等于2),因此时间戳计数器设置为2 + 1,则事件i的时间戳为3 。
这保证里关系b → i,即b发生在i之前。
情况二:接收到的消息的时间戳小于当前事件的时间戳
进程$P_0$中的事件c是,事件h发送的消息的接收事件。
在这里,c的时间戳不需要调整。消息中的时间戳为1,小于$P_0$准备分配给c的事件时间戳3 。
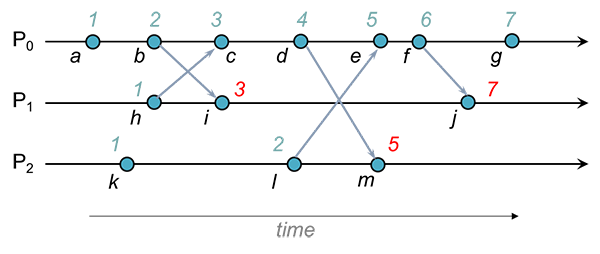
小结
使用Lamport时间戳,我们可以确保两个因果相关的事件将具有反映事件顺序的时间戳。例如,在Lamport因果意义上,事件h在事件m之前发生。因果事件的链为 h → c, c → d和 d → m。由于之前发生的关系是可传递的,因此我们知道 h → m(h在m之前发生)。Lamport时间戳反映了这一点。用于时间戳h(1)小于所述时间戳m(7)。
但是,仅通过查看时间戳,我们不能得出存在因果关系的结论。例如,因为k(1)的时间戳小于i(3)的时间戳,并不意味着k在i之前发生 。这些事件恰巧是并发的,但我们无法通过查看Lamport时间戳来辨别。我们需要采用其他技术才能做出确定。该技术即是Vector Clocks。
Vector Clocks
对于Vector Clocks,假设我们知道该组中的进程数(我们稍后将删除此限制)。
现在,我们的时间戳不再是单个数字,而是一个数字向量,每个元素都对应一个进程。每个进程都知道其在向量中的位置。
例如,在下面的示例中,向量元素对应于进程$processes (P_0, P_1, P_2)$。
与Lamport的算法一样,在将时间戳附加到事件之前,向量时间戳中与进程编号相对应的元素会增加。如果进程$P_0$具有四个顺序事件a,b,c,d,则它们将获得(1,0,0), (2, 0, 0), (3, 0, 0), (4, 0, 0)。如果进程$P_2$具有四个顺序事件a,b,c,d,则它们将获得(0,0,1), (0, 0, 2), (0, 0, 3), (0, 0, 4)。
如果事件是发送消息,则与该事件关联的整个向量将与消息一起发送。当某个进程接收到该消息时(该事件将被分配一个时间戳),接收进程将执行以下操作:
就像在时间戳标记任何本地事件一样,增加计数器在向量中的位置。
对接收到的向量与进程的时间戳向量进行逐元素比较。将进程的时间戳向量设置为较高的值:
1
2
3for (i=0; i < num_elements; i++) //循环每个元素。例子中num_elements为3
if (received[i] > system[i])//将较大的元素值赋值给当前进程的元素
system[i] = received[i];
例子🌰分配Vector Clocks
下图显示了和上面的例子相同事件集,但具有Vector Clocks分配。
事件b是向$P_1$发送消息。 该消息包含事件b的时间戳 (2, 2, 0) 。
事件i是该消息的接收事件。 如果i是本地事件,它将获得时间戳(0, 2, 0)。 由于它是消息的接收事件,我们对接收到的时间戳和本地时间戳中的值进行逐元素比较,并选择每对数字中的最大值:
将(2, 0, 0)与收到的时间戳(0, 2, 0)进行比较。
- 第一个元素:2 vs. 0,取较大值2。
- 第二个元素:0 vs. 2,取较大值2。
- 第三个元素:0 vs. 0,相等取0。
因此,所得的向量为(2,2,0),并分配给事件i和系统时钟。 $P_1$上的下一个本地事件将被标记为(2,2 + 1,0)或(2,3,0)。

如何确定事件发生的顺序
要确定两个事件是否同时发生,应对相应时间戳进行逐元素比较。
如果时间戳记V的每个元素小于或等于时间戳记W的相应元素,则V因果顺序在W之前,并且事件不是并发的。
如果时间戳记V的每个元素都大于或等于时间戳记W的相应元素,则W因果顺序在V之前,并且事件不是并发的。
如果这些条件都不适用,并且V中的某些元素大于W而其他元素小于W中的对应元素,则事件是并发的。
我们可以用伪代码对其进行总结:
1
2
3
4
5
6
7
8
9
10
11
12
13
14isconcurrent(int v[], int w[])
{
bool greater=false, less=false;
for (i=0; i < num_elements; i++) //循环每个元素。例子中num_elements为3
if (v[i] > w[i])
greater = true;
else (v[i] < w[i])
less = true;
if (greater && less)//有些元素大有些元素小
return true; /* 向量是并发的 */
else
return false; /* 向量不是并发的 */
}
例子🌰确定事件发生顺序
非并发事件:在上图中,e的时间戳小于j的时间戳,因为e中的每个元素都小于或等于j中的相应元素。 即5≤6、1≤3和2≤2。事件是因果相关的,并且e→j
并发事件:事件f和m是并发的。 当我们比较f和m的第一个元素时,我们看到f> m(6> 4)。 当比较第二个元素时,我们看到f = m(1 = 1)。 最后,当我们比较第三个元素时,我们看到f <m(2 <3)。 因此,我们不能说f的向量小于或大于m的向量。
改进
回想一下,我们必须假设我们知道组中的进程数,以便我们可以创建适当大小的向量。 在实际的实现中,情况并非总是如此。 而且,通信中可能不会涉及所有进程,从而导致不必要的大向量。
我们可以用一组元组替换向量,每个元组代表一个进程ID及其计数器:( { P0, 6 }, { P1, 3 }, { P2, 2 } )
当一个进程发送一个向量时,它发送它拥有的整个元组集。 当它收到一个向量并执行比较时,它会比较每个相关对。 例如,将$P_0$的值与接收到的向量中包含$P_0$的元组进行比较。 如果其中一组缺少任何进程ID,则将其隐式指定为0进行比较。 所得向量包含所有元组的超集。
例子🌰
例如,如果某个进程的系统矢量时钟为:( { P0, 6 }, { P1, 3 }, { P2, 2 } )
接收值为 ( { P1, 1 }, { P2, 5 }, { P3, 8 } )
产生的向量将是所有进程ID及其最大值的集合:( { P0, 6 }, { P1, 3 }, { P2, 5 }, { P3, 8 } )